集合
1.集合的好处
1.解决数组定义时必须先指定长度
2.解决数组必须存储同一类型的数据
3.使用数组进行增删改查太麻烦
4.集合可以存储任意多个对象,使用方便
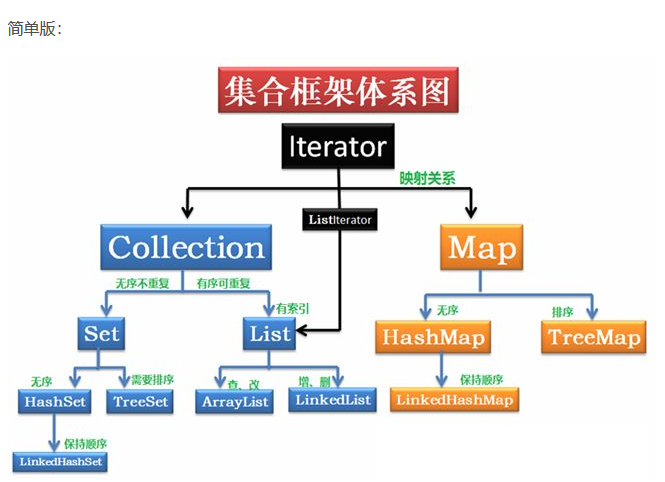
2.集合框架图
3.collection接口方法,已实现子类ArrayList来演示
3.1add添加单个元素
1
2
3
4
5
6
7
8
9
| public class work1 {
public static void main(String[]args) {
List l1 = new ArrayList();
l1.add("haozi");
l1.add(123);
l1.add(true);
System.out.println(l1);
}
}
|
3.2remove删除指定元素
1
2
3
4
5
6
7
8
9
10
11
12
| public class work1 {
public static void main(String[]args) {
List l1 = new ArrayList();
l1.add("haozi");
l1.add(123);
l1.add(true);
System.out.println(l1);
l1.remove(0);
l1.remove(true);
System.out.println(l1);
}
}
|
3.3contains查找元素是否存在
1
2
3
4
5
6
7
8
9
10
11
12
13
| public class work1 {
public static void main(String[]args) {
List l1 = new ArrayList();
l1.add("haozi");
l1.add(123);
l1.add(true);
System.out.println(l1);
l1.remove(0);
l1.remove(true);
System.out.println(l1);
System.out.println(l1.contains(true));
}
}
|
3.4size获取元素个数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| public class work1 {
public static void main(String[]args) {
List l1 = new ArrayList();
l1.add("haozi");
l1.add(123);
l1.add(true);
System.out.println(l1);
l1.remove(0);
l1.remove(true);
System.out.println(l1);
System.out.println(l1.contains(true));
System.out.println(l1.size());
}
}
|
3.5isEmpty判断是否为空
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| public class work1 {
public static void main(String[]args) {
List l1 = new ArrayList();
l1.add("haozi");
l1.add(123);
l1.add(true);
System.out.println(l1);
l1.remove(0);
l1.remove(true);
System.out.println(l1);
System.out.println(l1.contains(true));
System.out.println(l1.size());
System.out.println(l1.isEmpty());
}
}
|
3.6clear清空
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| public class work1 {
public static void main(String[]args) {
List l1 = new ArrayList();
l1.add("haozi");
l1.add(123);
l1.add(true);
System.out.println(l1);
l1.remove(0);
l1.remove(true);
System.out.println(l1);
System.out.println(l1.contains(true));
System.out.println(l1.size());
System.out.println(l1.isEmpty());
l1.clear();
}
}
|
3.7addAll添加多个元素
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| public class work1 {
public static void main(String[]args) {
List l1 = new ArrayList();
l1.add("haozi");
l1.add(123);
l1.add(true);
System.out.println(l1);
l1.remove(0);
l1.remove(true);
System.out.println(l1);
System.out.println(l1.contains(true));
System.out.println(l1.size());
System.out.println(l1.isEmpty());
l1.clear();
List l2 = new ArrayList();
l2.add(1);
l2.add(2);
l1.addAll(l2);
System.out.println(l2);
}
}
|
3.8containsAll查找多个元素是否存在
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| public class work1 {
public static void main(String[]args) {
List l1 = new ArrayList();
l1.add("haozi");
l1.add(123);
l1.add(true);
System.out.println(l1);
l1.remove(0);
l1.remove(true);
System.out.println(l1);
System.out.println(l1.contains(true));
System.out.println(l1.size());
System.out.println(l1.isEmpty());
l1.clear();
List l2 = new ArrayList();
l2.add(1);
l2.add(2);
l1.addAll(l2);
System.out.println(l2);
System.out.println(l1.containsAll(l2));
}
}
|
3.9removeAll删除多个元素
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| public class work1 {
public static void main(String[]args) {
List l1 = new ArrayList();
l1.add("haozi");
l1.add(123);
l1.add(true);
System.out.println(l1);
l1.remove(0);
l1.remove(true);
System.out.println(l1);
System.out.println(l1.contains(true));
System.out.println(l1.size());
System.out.println(l1.isEmpty());
l1.clear();
List l2 = new ArrayList();
l2.add(1);
l2.add(2);
l1.addAll(l2);
System.out.println(l2);
System.out.println(l1.containsAll(l2));
l1.add(3);
l1.removeAll(l2);
System.out.println(l1);
}
}
|
4.遍历方式
4.1 for增强遍历
1
2
3
4
5
6
7
8
9
10
11
| public class work1 {
public static void main(String[]args) {
List l1 = new ArrayList();
l1.add("haozi");
l1.add(123);
l1.add(true);
for(Object i:l1) {
System.out.println(i);
}
}
}
|
4.2案例:创建3个dog对象,放入arraylist中,并遍历
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
| public class work1 {
public static void main(String[]args) {
ArrayList l1 = new ArrayList();
dog d1 = new dog ("dog1",18);
dog d2 = new dog ("dog2",19);
dog d3 = new dog ("dog3",20);
l1.add(d1);
l1.add(d2);
l1.add(d3);
for(Object dog:l1) {
System.out.println(dog);
}
}
}
class dog {
String name;
int age;
public dog(String name,int age) {
this.name = name;
this.age = age;
}
public String getname() {
return name;
}
public void setname(String name) {
this.name=name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "dog [name=" + name + ", age=" + age + "]";
}
}
|
4.3案例:利用书的价格排序
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
| public class work1 {
public static void main(String[]args) {
List l1 = new ArrayList();
book d1 = new book ("book1",200,"zz1");
book d2 = new book ("book2",100,"zz2");
book d3 = new book ("book3",300,"zz3");
l1.add(d1);
l1.add(d2);
l1.add(d3);
for(int i = 0;i<l1.size()-1;i++) {
for(int j = 0;j<l1.size()-1-i;j++) {
book b1 = (book)l1.get(j);
book b2 = (book)l1.get(j+1);
if(b1.getJg()>b2.getJg()) {
l1.set(j, b2);
l1.set(j+1, b1);
}
}
}
for(Object book:l1) {
System.out.println(book);
}
}
}
class book {
String name;
int jg;
String zz;
public book(String name,int jg,String zz) {
this.name=name;
this.jg = jg;
this.zz = zz;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getJg() {
return jg;
}
public void setJg(int jg) {
this.jg = jg;
}
public String getZz() {
return zz;
}
public void setZz(String zz) {
this.zz = zz;
}
@Override
public String toString() {
return "book [name=" + name + ", jg=" + jg + ", zz=" + zz + "]";
}
}
|
5.ArrayList的注意事项
1.ArrayList 是由数组来实现数据存储的
2.多线程不建议使用ArrayList
6.List接口实现类-ArrayList底层结构
1.ArrayList中维护了一个Object类型的数组elementData。
2.当创建ArrayList对象时,如果使用的是无参构造器,则初始elementData容量为0,第一次添加,则扩容elementData为10,如果需要再次扩容,则扩容elementData为1.5倍。
3.如果使用的是指定大小的构造器,则初始elementData容量为指定大小,如果需要扩容,则直接扩容elementData为1.5倍
7.Vector底层结构
1.Vector是可变数组,安全(针对线程),效率不高,如果是无参,默认10,满后,就按2倍扩容,如果指定大小,则每次直接按2倍扩充
8.List接口实现类-LinkedList的全面说明
1.LinkedList实现了双向链表的双端队列特点
2.可以添加任意元素(元素可以重复),包括null
3.线程不安全,没有实现同步
4.LinkedList中维护了两个属性first和last分别指向头节点和尾节点
5.每个结点Node对象,里面又维护了prev(前驱)、next(后继)、item(存放数据)三个属性(双向链表)。
6.所以LinkedList的元素的添加和删除,不是通过数组完成的,相对来说效率最高
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
LinkedList linkedList = new LinkedList();
for(int i = 1;i<=2;i++){
linkedList.add(i);
linkedList.remove();
linkedList.set(1,999);
Object o = linkedList.get(1);
}
for(Object o1:linkedList){
System.out.println(o1);
}
for(int i = 0;i< linkedList.size();i++){
System.out.println(linkedList.get(i));
}
Iterator iterator = linkedList.itreator();
while(iterator.hasNext()){
Object next = iterator.next();
System.out.println("next");
}
|
9.ArrayList和LinkedList的比较
1.ArrayList是可变数组,增删效率低,数组扩容,改查效率高
2.LinkedList是双向链表,增删效率较高,可以通过链表追加,但是改查的效率较低
3.我们可以看操作的数据是增删的操作多还是改查的操作多而去选择ArrayList和LinkdeList
10.Set接口常用的方法
1.实现Set接口的子类是无序(添加和取出的顺序不一致),没有索引
2.不允许插入重复元素,最多包含一个null
3.Set接口的实现类有HashSet和TreeSet
4.Set接口和List接口一样,Set接口也是Collection的子接口,因此常用方法和Collection接口一样,遍历方式也一样,但是不能使用索引的方式来获取了
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
Set set = new HashSet();
set.add("1");
set.add("2");
set.add("1");
set.add(null);
Iterator iterator = linkedList.itreator();
while(iterator.hasNext()){
Object next = iterator.next();
System.out.println("next");
}
for(Object o : set){
System.out.println(o);
}
|
11.Set接口实现类-HashSet
1.HashSet实现了Set接口
2.HashSet实际上是HashMap,底层是数组+链表
3.只可以存放一个null值
4.输出后的顺序和插入的顺序不同,但每次取出的顺序是一致的,而且没有重复的元素/对象
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| Set hashSet = new HashSet();
hashSet.add("1");
hashSet.add("1");
hashSet.add(new Dog("tom"));
hashSet.add(new Dog("tom"));
hashSet.add(new String("haozi"));
hashSet.add(new String("haozi"));
class Dog{
private String name;
public Dog(String name){
this.name = name;
}
}
|
11.1.HashSet底层机制
1.HashSet的底层是HashMap
2.添加一个元素时,先得到hash值-会转成->索引值
3.找到存储数据表table,看这个索引位置是否已经存放了元素,如果没有,则直接插入
4.如果有,调用equals比较,如果相同,就放弃添加,如果不相同,则添加到最后
5.如果一条链表的元素个数到达了8,并且table的大小大于等于了64就会进行树化(红黑树),否则仍然采用数组扩容机制
13.Set接口实现类-LinkedHashSet
1.它是HashSet的子类
2.底层是一个LinkedHashMap,底层是一个数组table(数组)+双向链表
3.根据hashcode值决定存放位置
4.不允许添加重复元素
5.加入的顺序和取出的顺序一致
6.添加第一次时,直接将数组table扩容到16
14.Map接口特点
1.Map与collection并列存在
2.Map中的key(hash得到的,就是数组的列位置,不可以重复)和value(key哈希得到后的位置数组链表的值)可以是任何引用数据类型
3.Map中的key不允许重复,当有相同的key则替换为最新的
4.Map中的value可以重复
5.Map中key可以分为null,value也可以为null,但是key为null只能有一个
6.常用String类作为Map的key
7.key和value之间存在单向一对一关系,通过key总能找到value
8.Map存放数据的key-value是一对k-v,存放在一个HashMap$Node中的,又因为Node实现了Entry接口,所以有一些书上说一对k-v就是一个Entry
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| Map map = new HashMap();
map.put("no1","haozi");
map.put("no2","lihao");
Set set = map.entrySet();
System.out.println(set.getclass());
for(Object obj : set){
System.out.println(obj.getclass());
Map.Entry entry = (Map.Entry) obj;
System.out.println(entry.getKey()+"-"+entry.getValue());
}
|
15.Map接口方法
1.put 添加
1
2
3
4
| Map map = new HashMap();
map.put("邓超",new Book("",100));
map.put("邓超","孙俪");
map.put("王宝强","马蓉");
|
2.remove 根据键删除映射关系
3.get 根据键获取值
1
| Object key = map.get("邓超");
|
4.size 获取元素个数
1
| System.out.println(map.size());
|
5.isEmpty 判断个数是否为0
1
| System.out.println(map.isEmpty());
|
6.clear 清除
7.containsKey 查找键是否存在
1
| System.out.println(map.containsKey("邓超"));
|
16.Map遍历方式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| Map map = new HashMap();
map.put("邓超","孙俪");
map.put("王宝强","马蓉");
map.put("宋茜","马蓉");
map.put("刘令博",null);
map.put(null,"刘亦菲");
map.put("鹿晗","关晓彤");
Set keset = map.keySet();
for(Object key: keset){
System.out.println(key+"—"+map.get(key));
}
Collection values = map.values();
for(Object value : values){
System.out.println(value);
}
|
17.Map接口实现类-HashMap
1.Map接口的常用实现类是:HashMap、Hashtable和propreties
2.HashMap的使用频率较多
3.HashMap是以key-val对的方式来存储数据的
4.key不允许重复,值可以重复,如果添加相同的key,那么会覆盖原来的key-val
5.与HashSet一样,不保证映射的顺序,底层还是Hash表的方式存储的
6.线程不安全
17.1 HashMap底层机制
1.扩容机制:和HashSet相同
2.HashMap底层维护了Node类型的数组table,默认为null
3.当创建对象时,将加载因子(loadfactor)初始化为0.75
4.第一次添加,则需要扩容table容量为16,临界值为12
5.以后再次扩容为table容量的2倍,临界值为原来的2倍,以此类推
6.如果一条链表的元素个数超过8并且table的大小>=默认64,就会进行树化(红黑树)
7.底层也是数组+链表+红黑树
案例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
| package Arrays;
import java.util.*;
public class work7 {
public static void main(String[]args) {
HashMap hashMap = new HashMap();
hashMap.put(1, new yg("haozi",180001,1));
hashMap.put(2, new yg("haozi2",180,2));
hashMap.put(3, new yg("haozi3",18001,3));
Set keyset = hashMap.keySet();
for(Object key: keyset) {
yg y = (yg) hashMap.get(key);
if(y.getGz()>18000) {
System.out.println(y);
}
}
}
}
class yg{
String name;
double gz;
int id;
public yg(String name,double gz,int id) {
this.name=name;
this.gz=gz;
this.id=id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public double getGz() {
return gz;
}
public void setGz(double gz) {
this.gz = gz;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
@Override
public String toString() {
return "yg [name=" + name + ", gz=" + gz + ", id=" + id + "]";
}
}
|
18.Map接口实现类-Hashtable
1.存放的元素是键值对:即 K-V
2.hashtable的键和值都不能为null
3.hashtable的使用方法基本上和HashMap一样
4.hashtable的线程是安全的,hashMap的线程是不安全的
5.数组初始化大小为11,临界值是8,每次扩容原大小*2+1
1
2
| Hashtable table = new Hashtable();
table.put("haozi","100");
|
19.Hashtable的子类-Properties
1.也是使用一种键值对的形式来保存数据
2.不允许为null
3.重复值会替换
4.特点类似于Hashtable类似
5.Properties 还可以用于从xxx.properties文件中,加载数据到Properties类对象,并进行读取和修改
1
2
3
4
5
6
| Properties properties = new Properties();
properties.put("john",100);
System.out.println(properties.get("john"));
properties.remove("john");
properties.put("john","haozi");
|
20.如何选择集合实现类
1.先判断存储的类型(一组对象[单列]或一组键值对[双列])
2.一组对象[单列]:Collection接口
允许重复:List
增删多:LinkedList[底层维护了一个双向链表]
改查多:ArrayList[底层维护Object类型的可变数组]
不允许重复:Set
无序:HashSet[底层是HashMap,维护了一个哈希表,数组+链表+红黑树]
排序:TreeSet
插入和取出顺序一致:LinkedHashSet,维护数组+双向链表
3.一组键值对[双列]:Map
键无序:HashMap[底层是:哈希表 jdk8:数组+链表+红黑树]
键排序:TreeMap
键插入和取出顺序一致:LinkedHashMap
读取文件:Properties
21.Set接口实现类-TreeSet
1.与HashSet的区别就是TreeSet可以排序
2.当使用无参构造器创建TreeSet时候,它仍然是无序的
3.使用TreeSet提供的一个构造器可以传入一个比较器(匿名内部类),并指定排序规则
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| TreeSet treeset = new TreeSet();
TreeSet treeset2 = new TreeSet(new Comparator(){
public int compare(Object o1,Object o2){
return ((String)o1).compareTo((String) o2);
}
});
treeset.add ("jack");
treeset.add ("tom");
treeset.add ("sp");
treeset.add ("a");
|
22.Map接口实现类-TreeMap
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
TreeMap treeMap = new TreeMap(new Comparator(){
public int compare(Object o1,Object o2){
return ((String)o2).compareTo((String)o1);
}
});
treemap.put ("jack","杰克");
treemap.put ("tom","汤姆");
treemap.put ("sp","耗子");
treemap.put ("a","例子");
System.out.println(treemap);
|
23.Collection工具类
1.Collections是一个操作Set、List和Map等集合的工具类
2.Collections是提供了一系列静态的方法对集合元素进行排序、查询和修改等操作
3.排序操作(均为static方法):
3.1reverse(List):反转List中元素的顺序
3.2shuffle(List):对List集合元素进行随机排序
3.3sort(List):根据元素的自然顺序对指定List集合元素按升序排序
3.4sort(List,Comparator):根据指定的Comparator产生的顺序对List集合元素进行排序
3.5swap(List,int,int):将指定list集合中的i处元素和j处元素进行交换
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| ArrayList a1 = new ArrayList();
list.add("tom");
list.add("smith");
list.add("king");
list.add("milan");
list.add("tom");
Collections.reverse(list);
System.out.println(list);
Collections.shuffle(list);
System.out.println(list);
Collections.sort(list);
System.out.println(list);
Collections.sort(list,new Comparator(){
public int compart(Object o1,Object o2){
if(o1 instanceof String){
return ((String)o2).length()-((String)o1).length();
}
}
});
System.out.println(list);
Collections.swap(list,0,1);
System.out.println(list);
|
3.6Object max(Collection):根据元素的自然顺序,返回给定集合中的最大元素
3.7Object max(Collection,Comparator):根据Comparator指定的顺序,返回给定集合中的最大元素
3.8Object min(Collection)
3.9Object min(Collection,Comparator)
3.10int frequency(Collection,Object):返回指定集合中指定元素的出现次数
3.11void copy(List dest,List src):将src中的内容复制到dest中
3.12boolean replaceAll(List list,Object oldVal,Object newVal):使用新值替换List对象的所有旧值
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
System.out.println(Collections.max(list));
Object maxObject = Collections.max(list,new Comparator(){
public int compare(Object o1,Object o2){
return ((String)o1.)length()-((String)o2).length();
}
});
System.out.println("长度最大的元素=" + maxObject);
System.out.println(Collections.frequency(list,"tom"));
ArrayList dest = new ArrayList();
for(int i = 0;i<list.size();i++){
dest.add("");
}
Collections.copy(dest,list);
System.out.println(dest);
Collections.replaceAll(list,"tom","汤姆");
System.out.println(list);
|